Possible Causes:
1-Network is unavailable or with high latency
Higher latency levels could impact the synchronization time, potentially leading to unsynchronized disaster recovery (DR). Additionally, if the connection between the primary database host and the standby database server is unstable, DR synchronization will fail.
Once DR is enabled, ensure the connection between the servers is stable and adjust the default latency and usage thresholds as needed.
In some cases, network bandwidth may be fully utilized, leaving no available bandwidth for DR synchronization.
Problem identification:
Verify the connection between the hosts, monitor the current network traffic, identify which applications are consuming the most bandwidth, and determine if the issue occurs when the DR is disconnected.
- For Windows OS, try using a network monitoring tool. You should check how much traffic flows through your network and which applications or devices use the most bandwidth. For Linux, use the “nload” command. Most monitoring tools help pinpoint when a problem starts, but you can’t compare time frames.
- Test network connectivity and validate the tnsnames.ora and listener.ora configurations. Additionally, try using the following commands: ‘traceroute’ for Linux or ‘tracert’ for Windows OS systems to identify where the network disruption occurs.
- Review your network logs to see if there are any unusual patterns. This might take considerable time. You can review the alert.log file on the standby database for errors.
- Try crossing the events of not sync log shipping and times when there might be a network latency that can cause delays.
- Monitor and analyze the data transfer load by doing an initiated test for that issue to identify the maximum data transfer rate possible using the network. You probably will need the help of an expert IT professional.
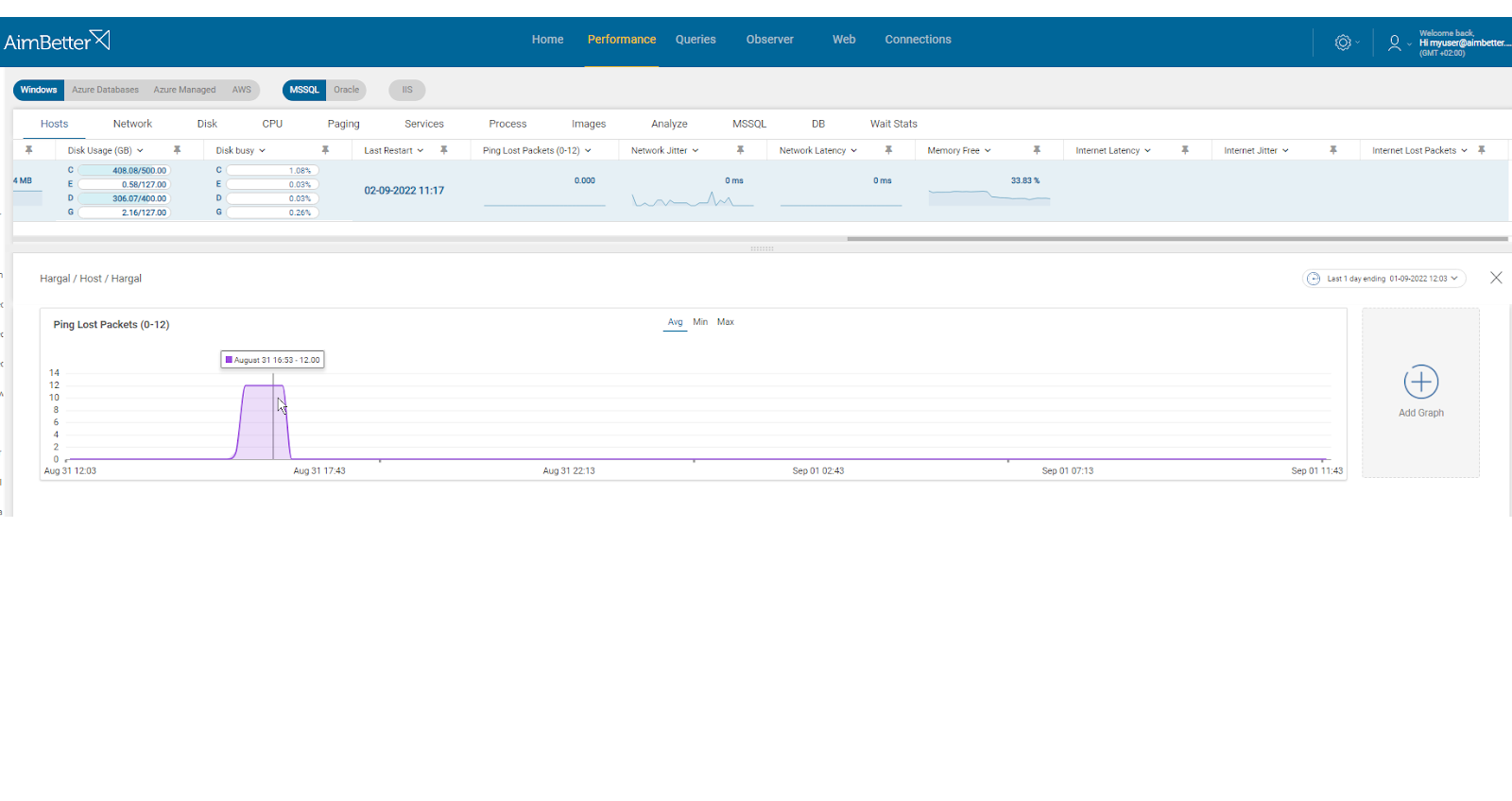
Recommended action:
Check what traffic occupies the bandwidth the most. Reschedule non-essential activity (e.g., virus scans, backup) to hours of lowest SQL demand where possible.
Enable ping between the primary and secondary Oracle DR server, and/or check firewall settings – ensure correct ports for Oracle DR (usually 1521 port).
Ideally, you should have a dedicated network between the servers involved in database log shipping. If the servers share a standard network with others, the adequate bandwidth available for log shipping communication will impact performance. Make sure it is in a high-bandwidth network. Lower bandwidth networks can adversely affect the performance of database log shipping.
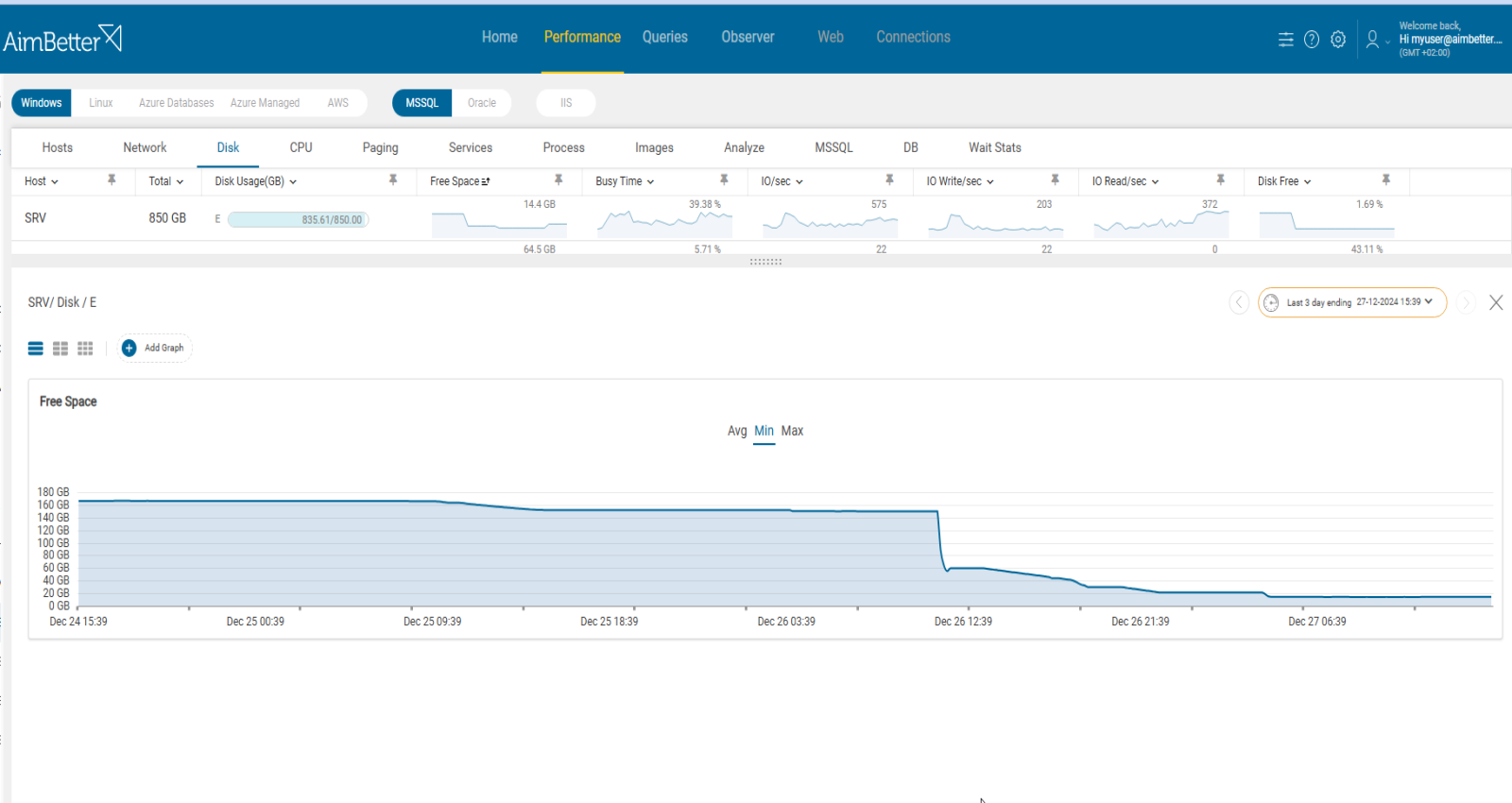
2- Insufficient Disk Space
When log shipping is used, storage is required for both the primary database backups and the standby database copy.
Additionally, storage is needed for historical changes (redo logs/archive logs), which is essential for recovery and synchronization. Oracle disaster recovery (DR) is not feasible without sufficient storage, and maintaining multiple copies of the database or ensuring data integrity becomes impossible.
Problem identification:
When checking errors related to an out-of-sync Oracle DR, look for error messages indicating disk space issues. If no such errors are found, review the disk properties to ensure enough storage is available for the DR process.
- For Windows OS, go to File Explorer and review the drive’s free space status. For Linux, try using the ‘df’ command, which provides data on the disk usage and availability.
- Another possibility is using the DR logs. Identify whether the error message is disk space-related or not.
- Use a performance monitor or any other system tool to identify large files for Windows OS. Take into account that you are limited to its current status. For Linux, use ‘lsblk’ command.
- For Windows OS, run a full scan of the disk’s content to locate its cause. For that, you need a specific desktop application, such as Treesize. Consider focusing on several file types on one of the scans, such as .tmp or dump application files, .bak files, and data files.
- When finding the cause, try to figure out why this exact file has increased and how to prevent it from happening again. Without proper events history, it might be hard to do.
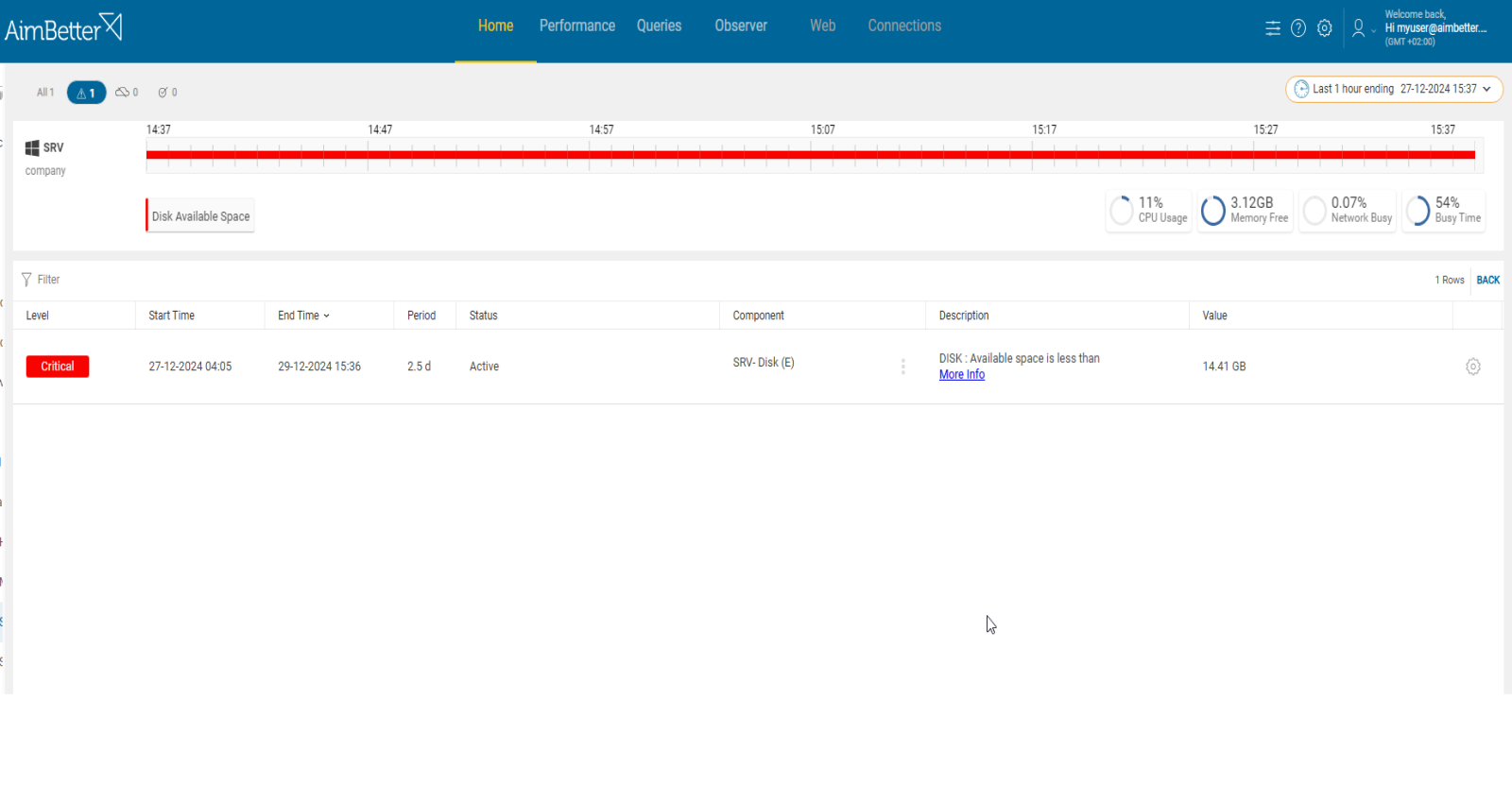
Recommended action:
Plan adequate storage capacity and monitor its usage over time. Make sure to separate the Oracle DR storage from other sources utilizing storage, whether it’s database, system, or application files.
For more information, see our article about host disk space.
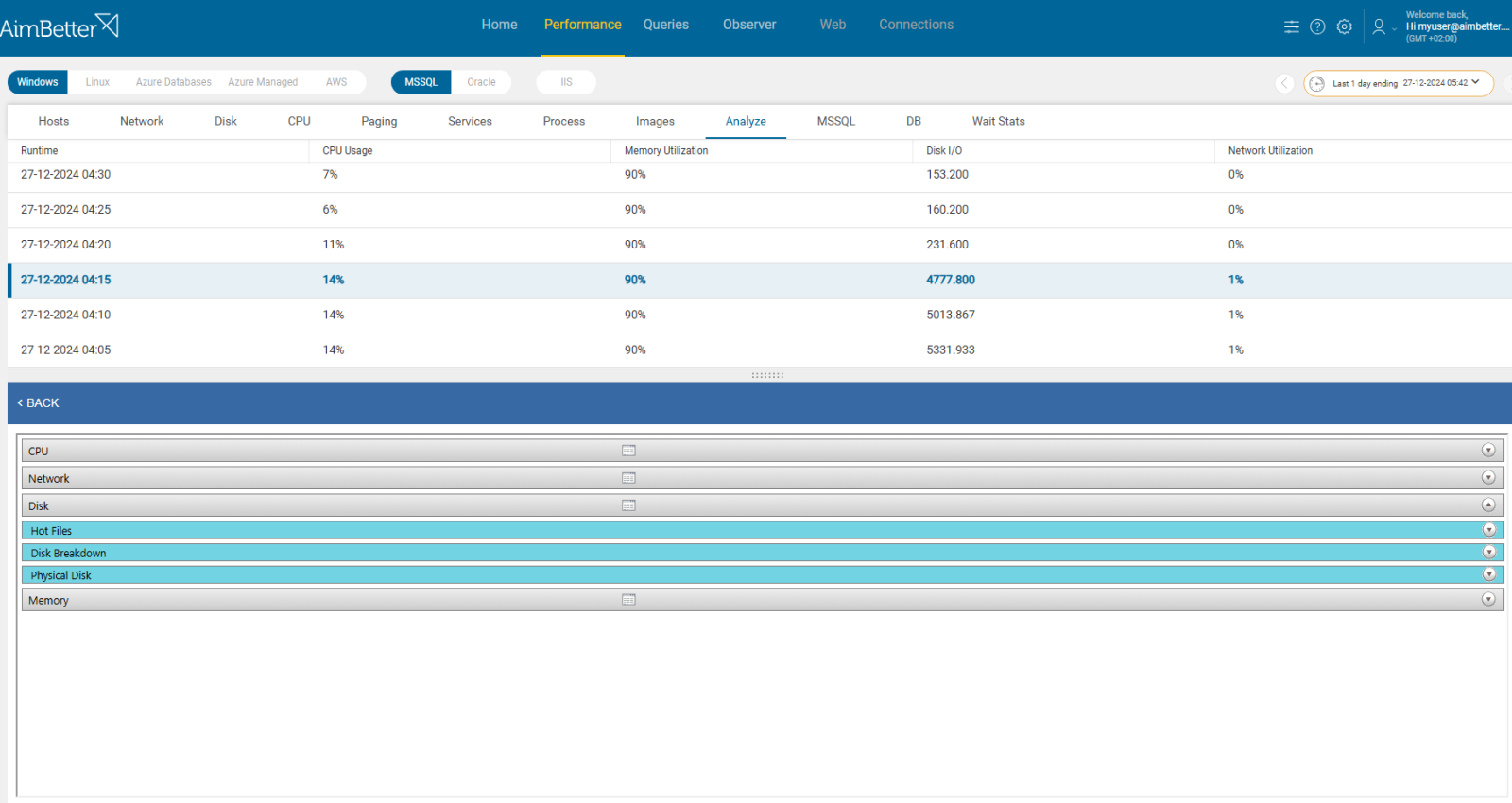
3- Hardware Overload
Limited resources for synchronization, such as high CPU usage, low available memory, or high disk I/O, can impact both the primary and/or standby database servers, leading to synchronization delays. For instance, when resources are nearly exhausted, replication queries may be delayed, which delays the transition process. This can cause the standby server to have outdated data, making Oracle DR unsynchronized.
Problem identification:
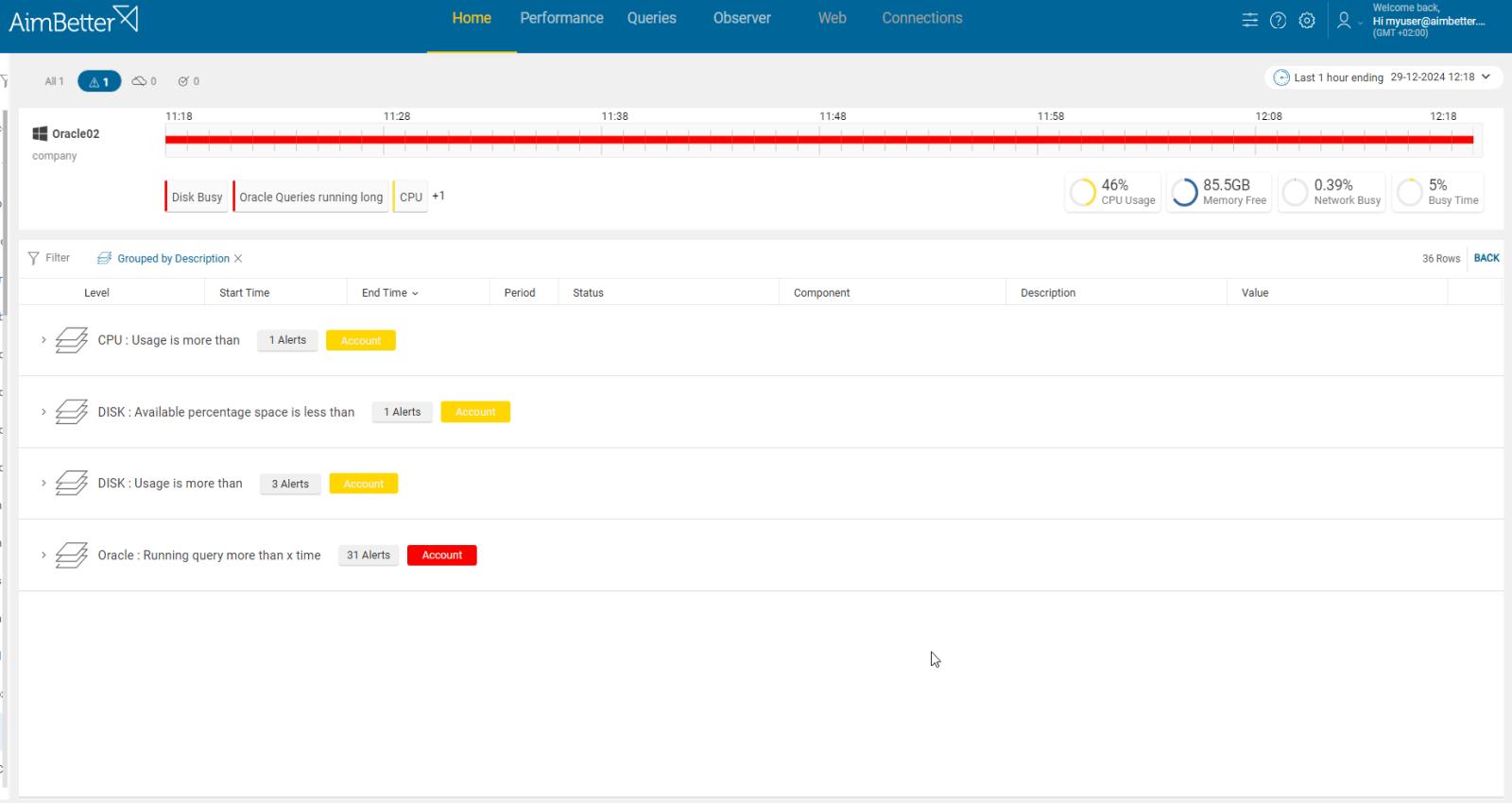
Identify errors related to OS resource usage or overload metrics involved with slow or failed replica operations. You should check it on the same period that the replica is done.
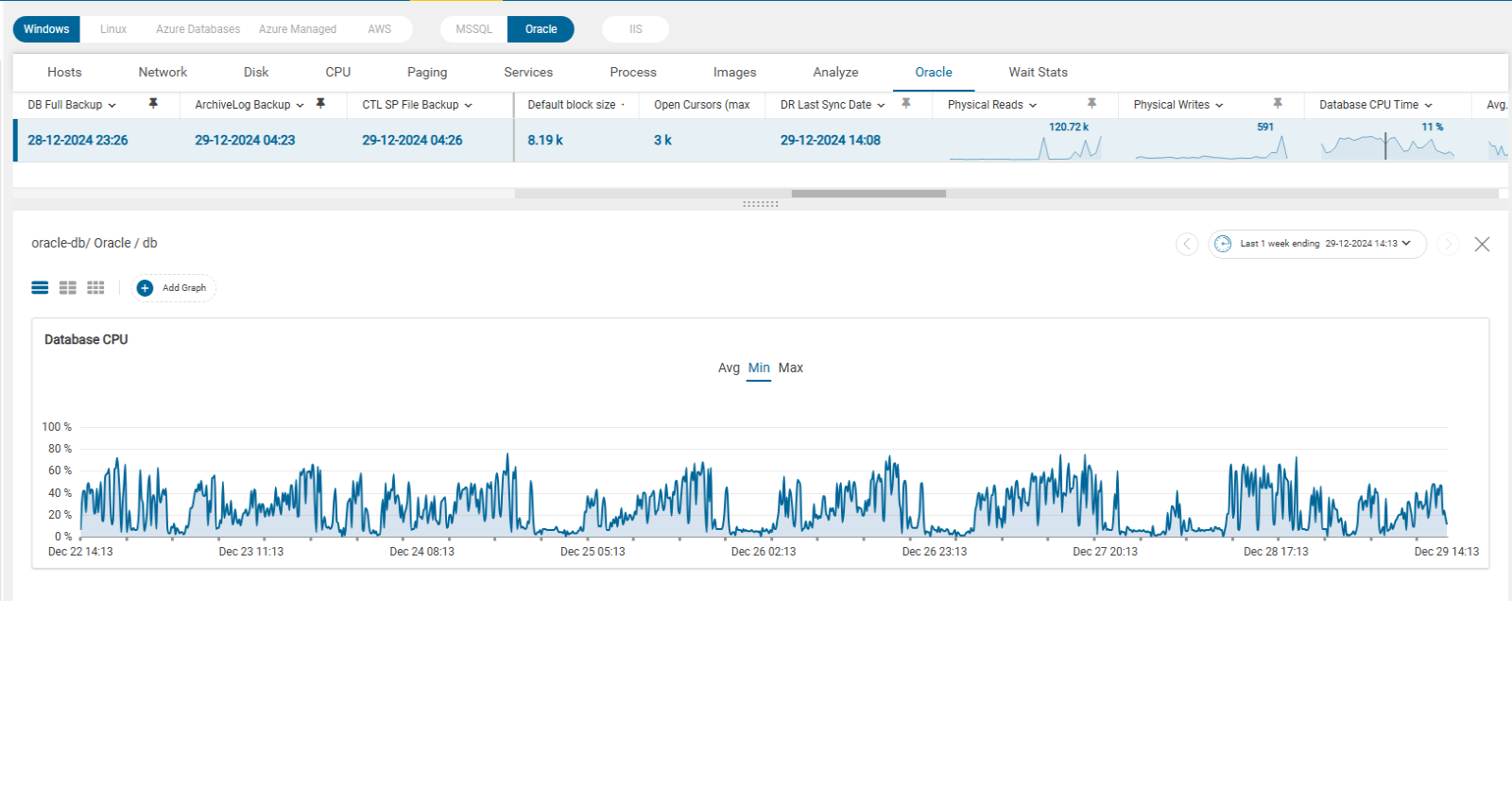
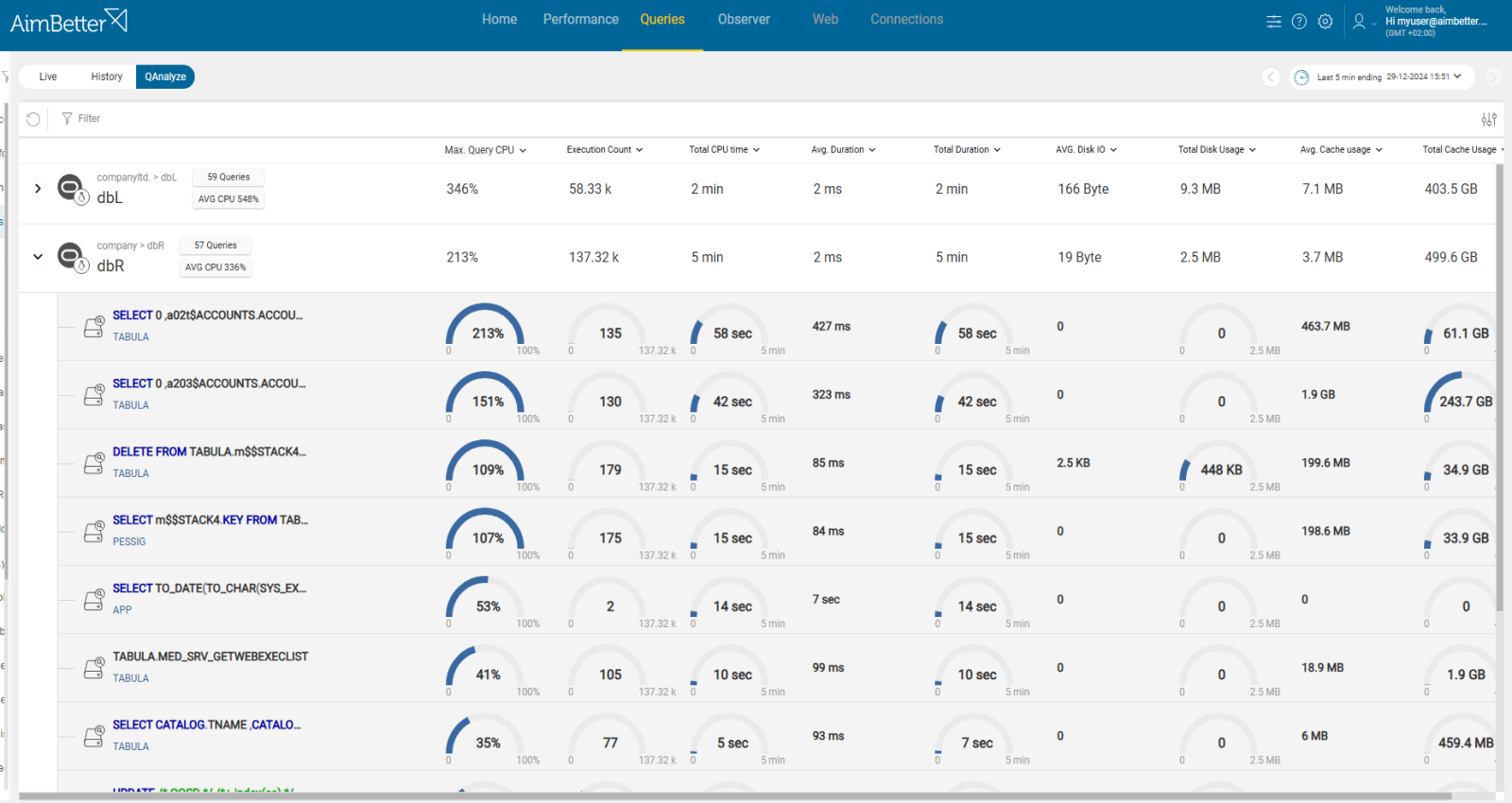
- Track performance over time and notice if queries are running slower. You can use tracking tools such as Active Session History (ASH) or AWR Reports to indicate Disk I/O or CPU usage.
- Investigate the system logs. For example, on Windows, you can check the event viewer logs and look for errors related to OS components, such as CPU, Memory, or disk I/O errors. You should also review database logs. This step might also be lengthy and without quarantine of results since it’s very vague what to look for.
- For Windows servers, check the Task Manager or Activity Monitor: use built-in OS tools such as Performance Monitor to identify if processes use too many resources. For Linux servers, you can use commands checking the status of OS resources: use ‘top’ command and look for Oracle processes (tnslsnr) for CPU, use ‘iostat’ for Disk I/O, use ‘free’ for used memory.
- Look for unnecessary startup programs: Some programs may start automatically and run in the background, consuming OS resources. You should disable it. It might take time to identify it.
- Check events of when Oracle DR turned to be not sync.
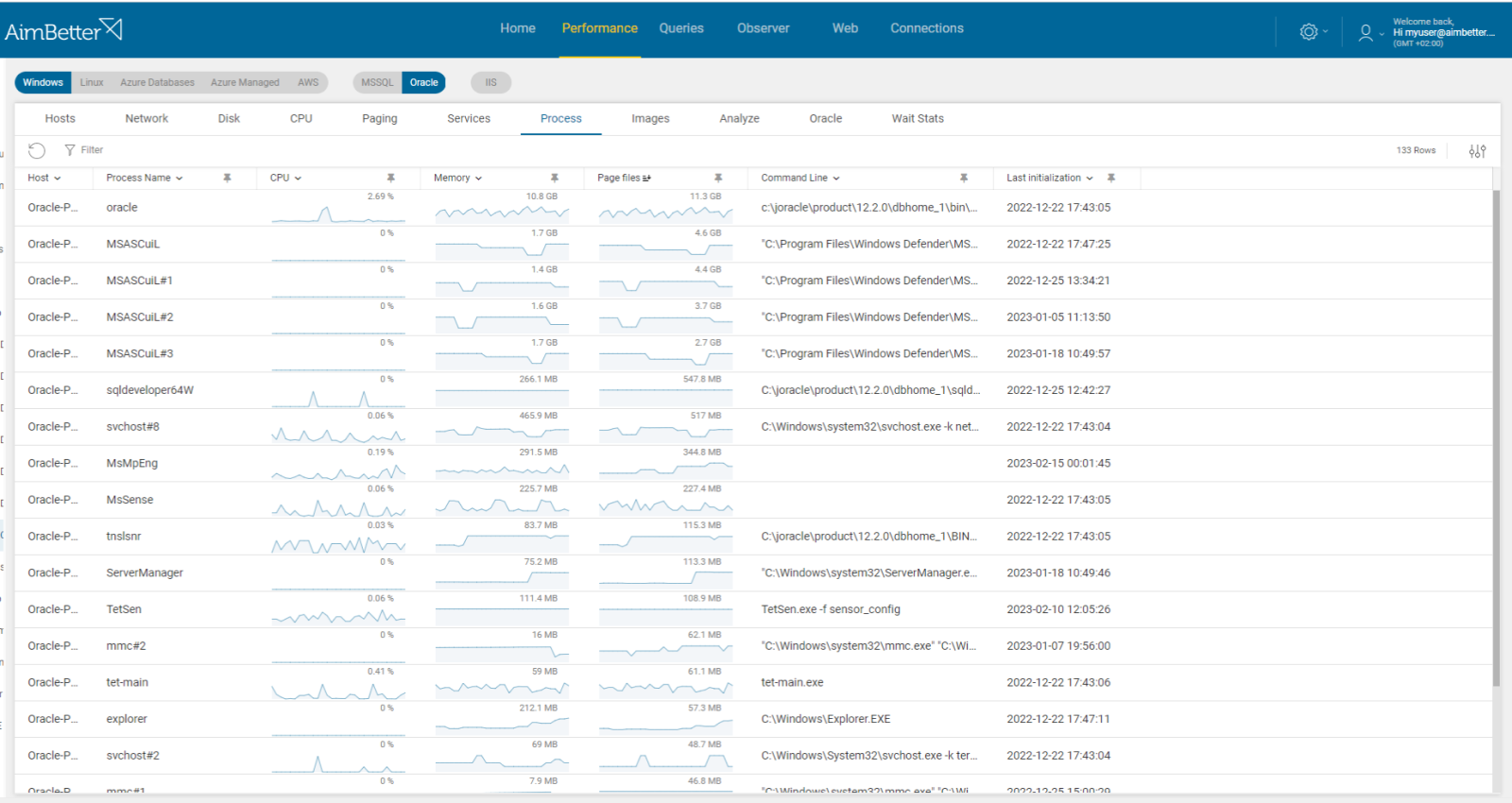
Recommended action:
When both primary and secondary are located on specific hardware, failure of this hardware will result in losing the vote and may cause the quorum to be lost—track which replica queries are still functioning to determine the point of failure. Take appropriate steps to bring the DR back to synchronization.
Ensure your software and drivers are up-to-date and keep track of the OS resources’ performance over time.
4- Open Transactions
Delays in the synchronization process can occur during long-running transactions or blocking situations. Over time, these delays may lead to failures, such as query timeouts.
In synchronous or semi-synchronous redo transport modes, the primary database waits for confirmation that the standby has received the redo. If there are open transactions on the primary database that have not yet been committed, the redo generated by those transactions cannot be entirely written to the redo logs until the transaction is committed. This can cause a delay in transmitting the redo to the standby.
Problem identification:
Look for open transaction events when the Oracle DR is in sync.
- Use Oracle monitoring tools (such as Enterprise Manager, AWR reports, or V$SESSION and V$TRANSACTION views) to identify open transactions on the primary database. These transactions might be holding up redo log generation or creating delays in shipping redo to the standby. This task requires a skilled DBA, which involves reviewing complex transaction logs and session activity. Look for cases where transactions are related to redo log generation or synchronization between the primary and standby databases.
- Check for exceptions, such as query timeouts or lock waits, which might indicate that transactions are not completed on time and could impact Data Guard synchronization.
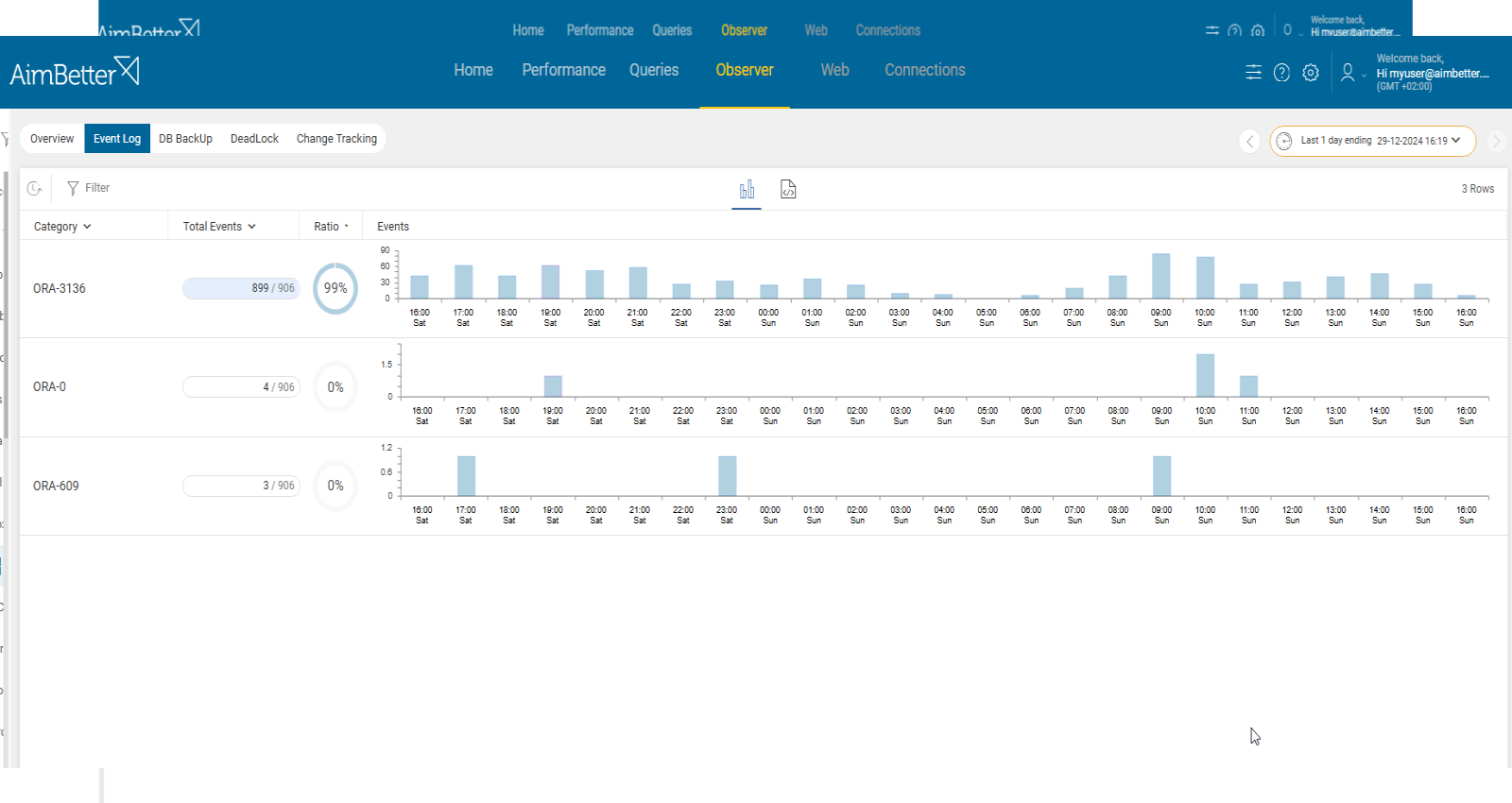
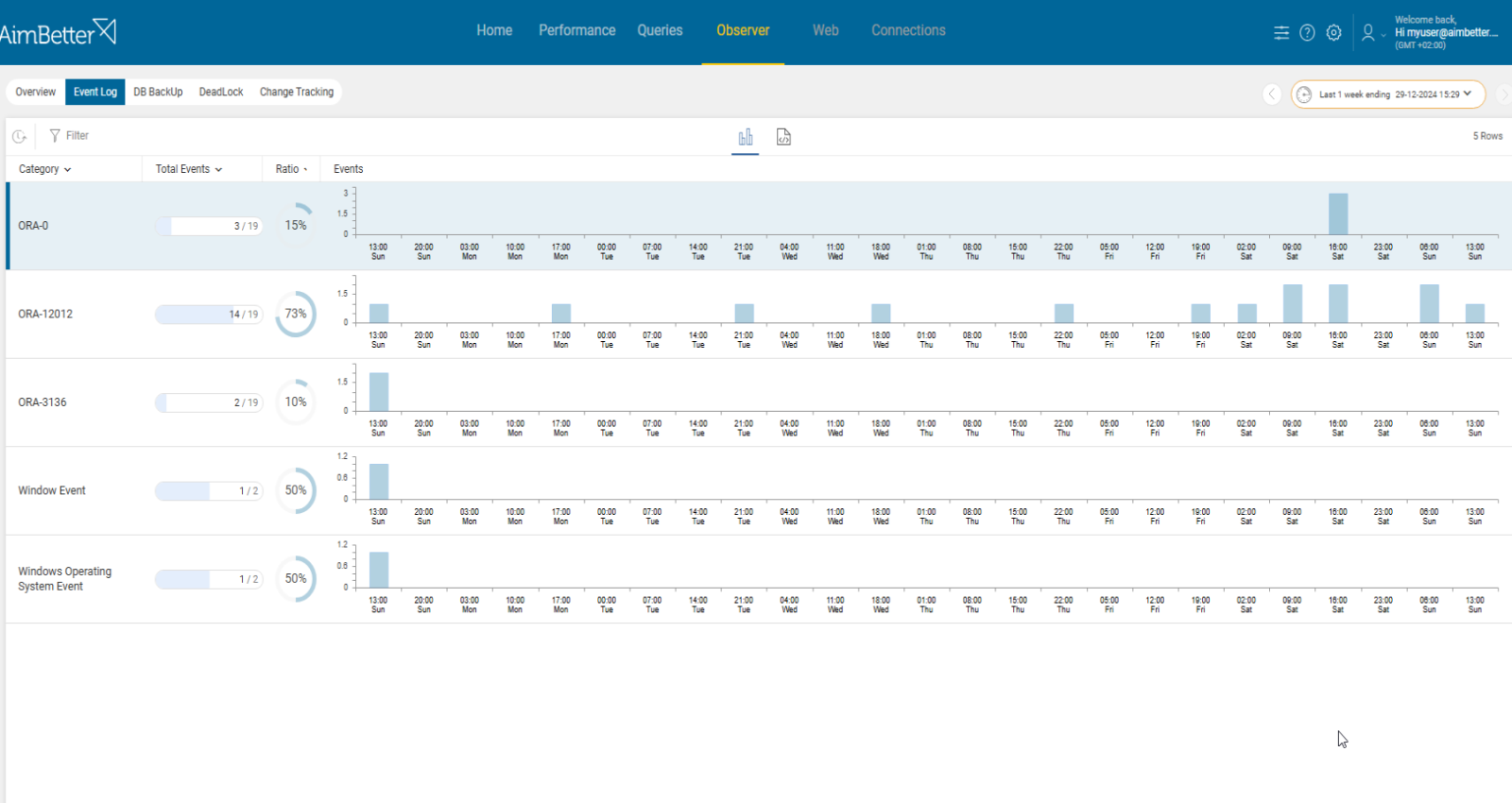
- Review the Oracle alert logs (both on the primary and standby) for any messages related to open transactions or blockings that could cause delays in the redo shipping. You can also check Data Guard logs.
- Use Data Guard views (such as V$DATAGUARD_STATUS or V$LOG_HISTORY) to track the synchronization status between the primary and standby databases. This allows you to see any unsynchronized periods or backlog in redo shipping and application. If your Data Guard configuration is in real-time apply mode, ensure the redo is applied on the standby as soon as it is received.
- Check the Data Guard status dashboard or use the SHOW CONFIGURATION command to monitor failovers and switchovers and ensure that the primary and standby databases are properly synchronized during role transitions.
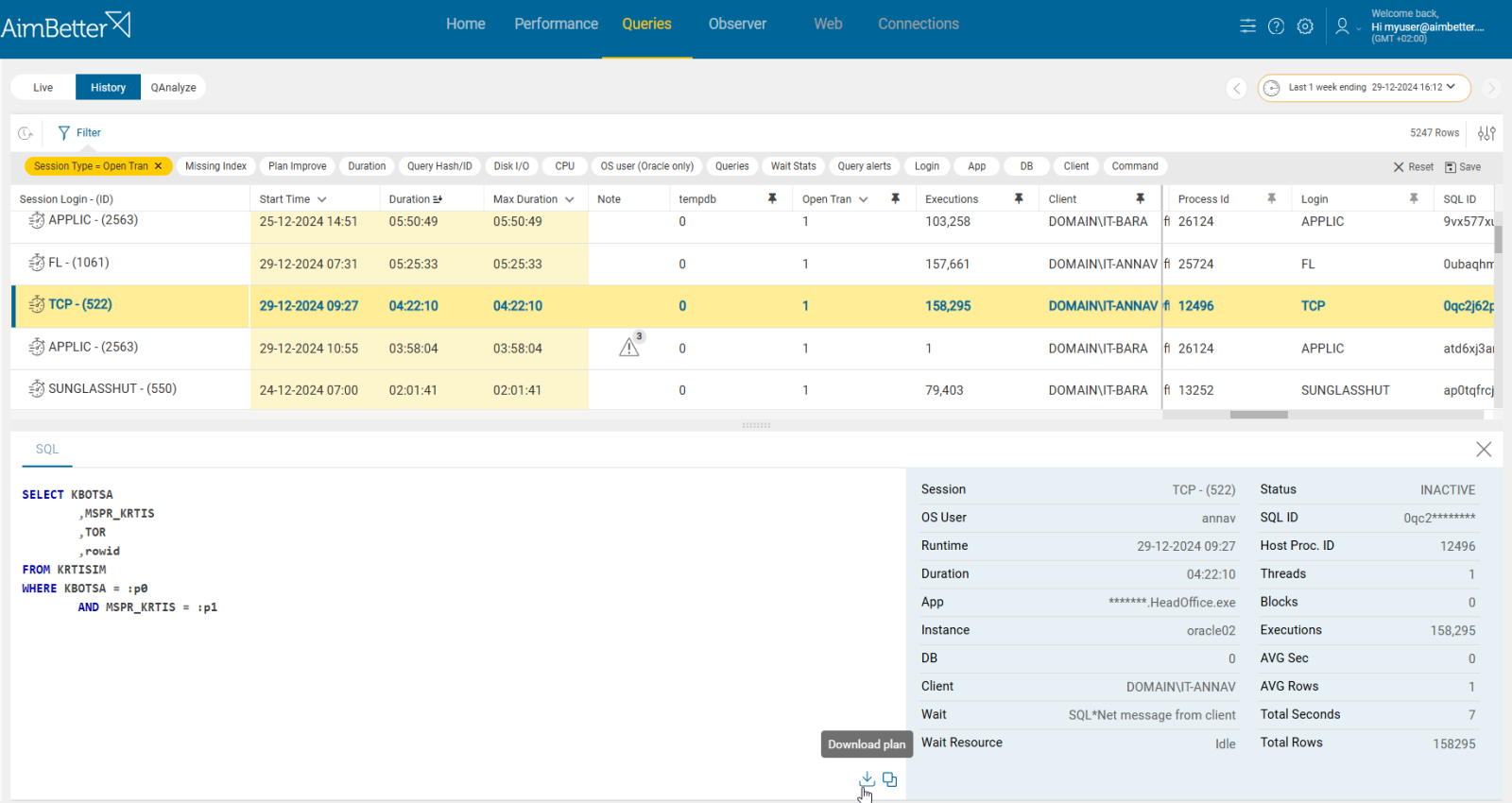
Recommended action:
Make sure the transactions don’t remain open for more time than needed. Check the database design and storage. Make sure to optimize the query’s execution plan if needed to reduce execution time.
If possible, use asynchronous redo transport mode for setups that can tolerate some lag between the primary and standby.
5-Errors or inadequate permissions
Incompatibilities between the primary and secondary instances participating in Oracle DR might cause errors in synchronization between them. Proper configuration and permission settings are critical to ensuring the smooth operation of Data Guard, as even minor issues in permissions or error handling can disrupt redo shipping and application.
Problem identification:
Identify errors in the primary and secondary servers during the execution process of the synchronization
- Use tracking tools to identify errors or permission issues in both servers. Try checking Alerts Logs, which includes Data Guard synchronization problems. It might take time and require a DBA. In parallel, try using Data Guard views, which help you track the status of redo transport, log shipping, and apply processes. These views can give you insights into whether your primary and standby databases are in sync or experiencing issues.
- Investigate all details collected and check which you should focus on that affects the synchronization status.
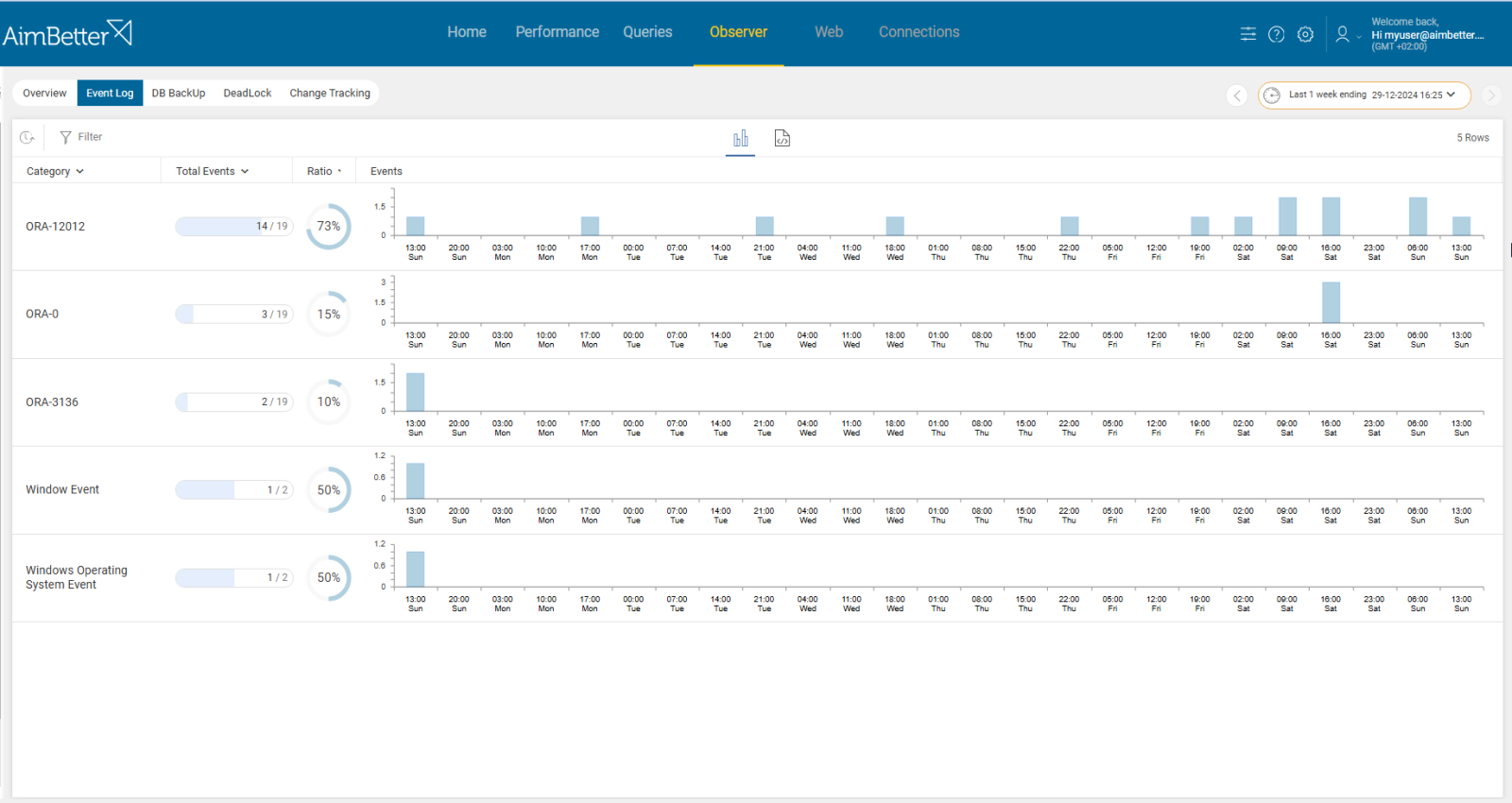
Recommended action:
Validate configuration consistency. Review recent changes to the environment that might have impacted synchronization. Ensure that the Oracle user (e.g., Oracle user) has the necessary read/write access to the required directories and archive logs on both primary and standby databases.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}