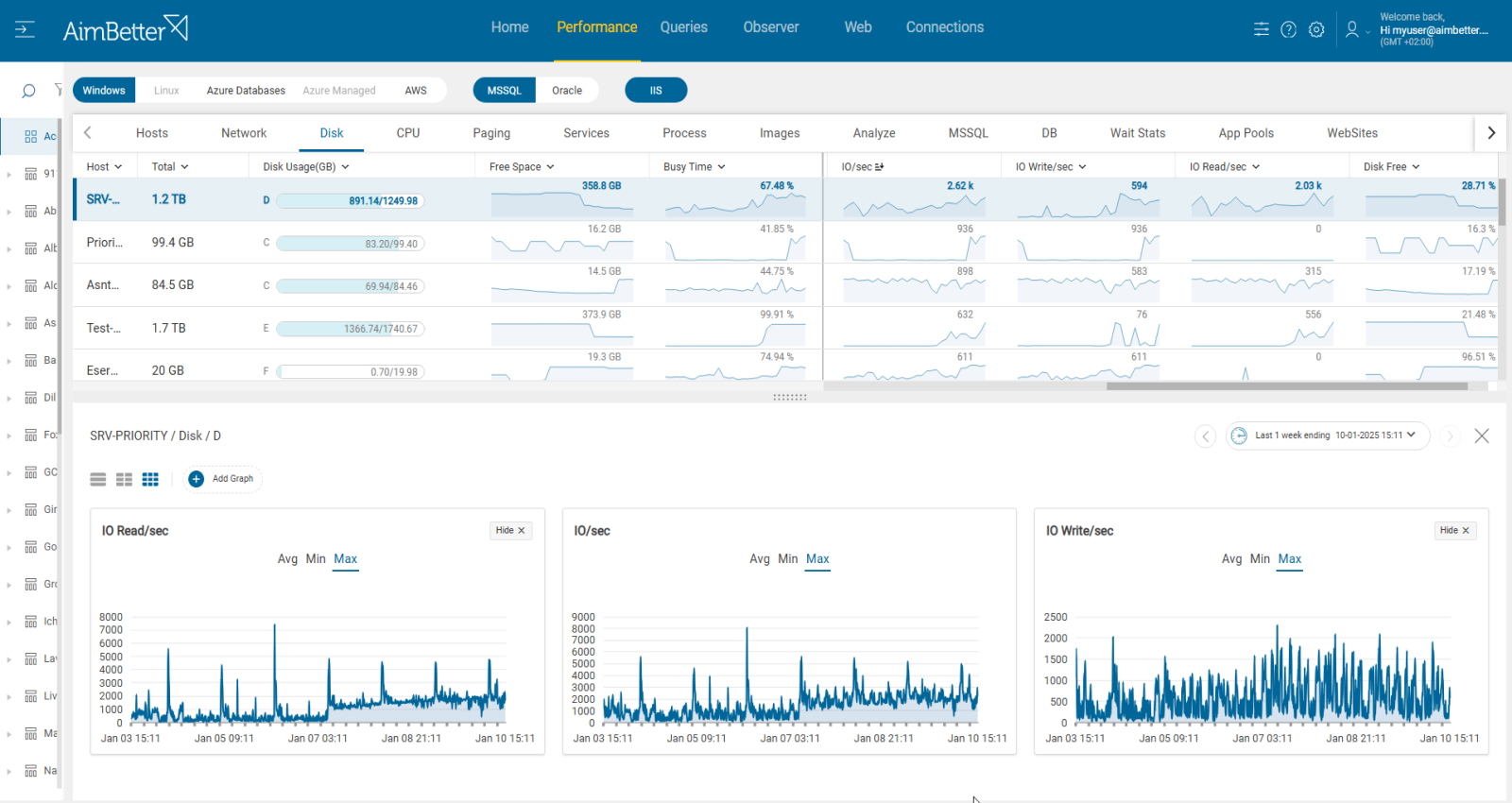
Disk IOPS (Input/Output Operations Per Second) measures the number of read and write operations performed on a storage device within a second. A Disk IOPS alert indicates that the number of IOPS is unusually high or low compared to the baseline activity, potentially affecting system performance.
Disk performance is a critical factor, and having both a Disk IOPS (Input/Output Operations Per Second) alert and a Disk Busy alert provides comprehensive coverage for detecting and diagnosing performance issues. By combining these metrics, you gain insights into both the quantity and intensity of disk activity, enabling more accurate diagnostics, for example:
- High Disk Busy + Low IOPS: Suggests large, resource-intensive operations are consuming disk bandwidth (e.g., large file transfers or backups).
- High IOPS + Low Disk Busy: Indicates many lightweight operations, potentially from high-frequency transactions or application activity.
- High Disk Busy + High IOPS: Warns of a saturated disk, likely due to a mix of high transaction volume and resource-heavy operations.
Expected behavior
The range of “regular” IOPS activity depends on several factors:
- Type of Workload:
- Transactional databases: Typically, IOPS are higher due to frequent small read/write operations.
- Analytical workloads: May involve fewer but larger sequential reads.
- Hardware Configuration:
- HDDs: Handle 50–200 IOPS on average.
- SSDs: Handle 5,000–50,000 IOPS, or even higher in enterprise setups.
- Baseline Usage Patterns:
- The normal range is determined by observing the system under typical operating conditions.
Possible causes
1- Operating system conflict Priority: Medium
Besides database functions, the server performs functions relating to other operating system activities, such as anti-virus scans, disk clean-up, OS updates, etc. If an unusually high level of these coincides with high database activities, there may be an excessive load on the disk from competing elements.
Problem identification:
Check the operating system activities and look for abnormal behavior.
1. Look for the anti-virus scan schedule. Antivirus software can sometimes conflict with the operating system or database activities and cause high disk IO. To identify which database activities are colliding with anti-virus scans, you will probably have to use tracking tools such as SQL Server Profiler for SQL Server or AWS for Oracle. This task requires DBA and might take time. It will also be inaccurate enough since checking from the current moment will not allow for comparison with similar events from the past.
2. Look for incompatible drives. Sometimes, the driver is not compatible with the operating system’s current activity. There is a chance for higher system activity that collides with the disks’ possible usage. Most operating systems do not have the correct tools that can check it.
3. Use Task Manager or other system tools on Windows and look for tasks consuming high disk I/O. This check won’t be precise since it focuses only on the exact moment, with no history of events. Try using commands to identify programs consuming disk I/O for Linux. For example, ‘io-top’ shows disk I/O usage by processes in real-time; ‘pidstat’ displays I/O statistics for individual processes.
4. Look for fragmented files. It might cause high disk I/O.
With our solution it’s easy to identify the root cause of the issue.
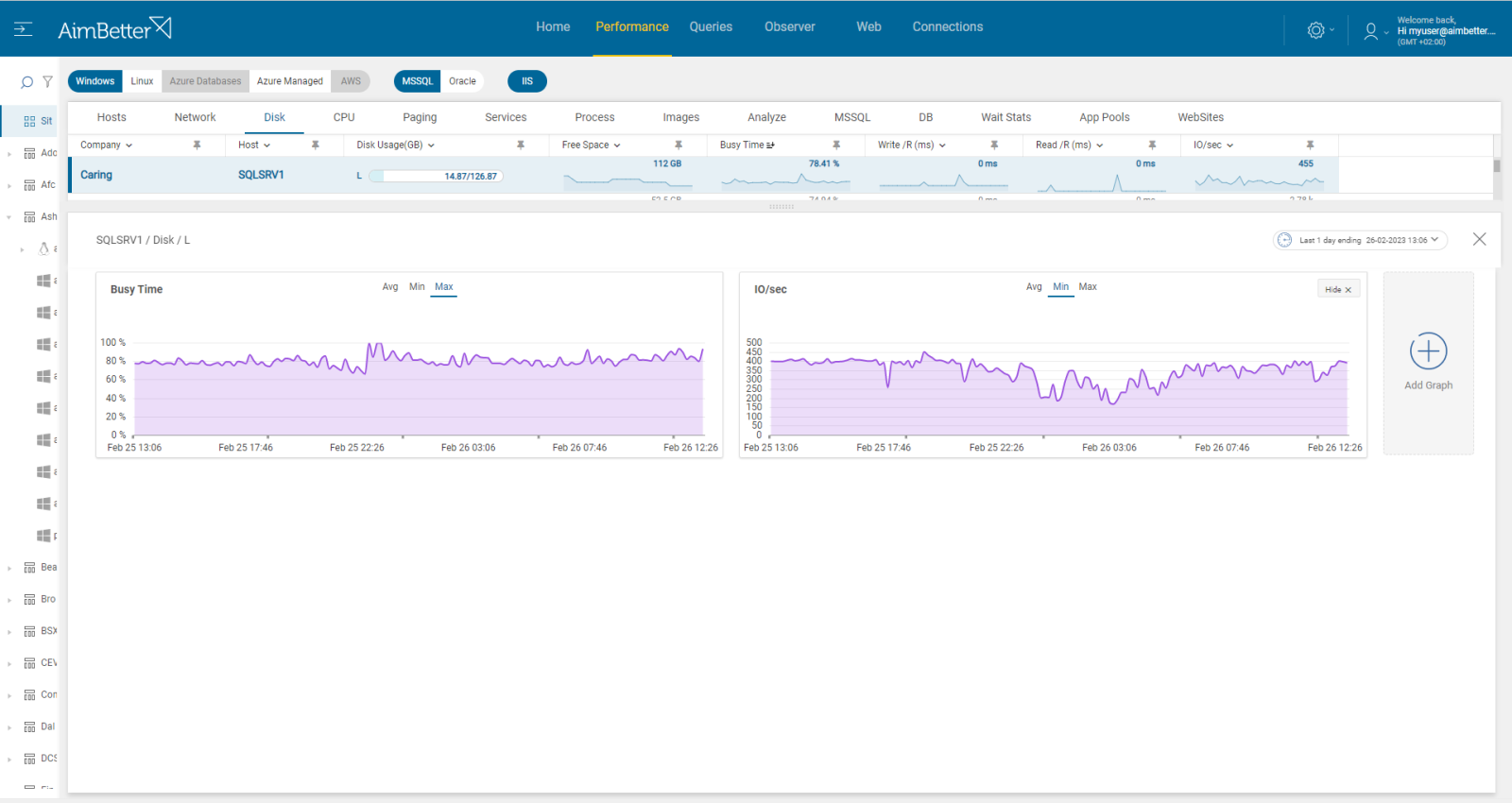
Each query has a note regarding an anti-virus scan while it’s running.
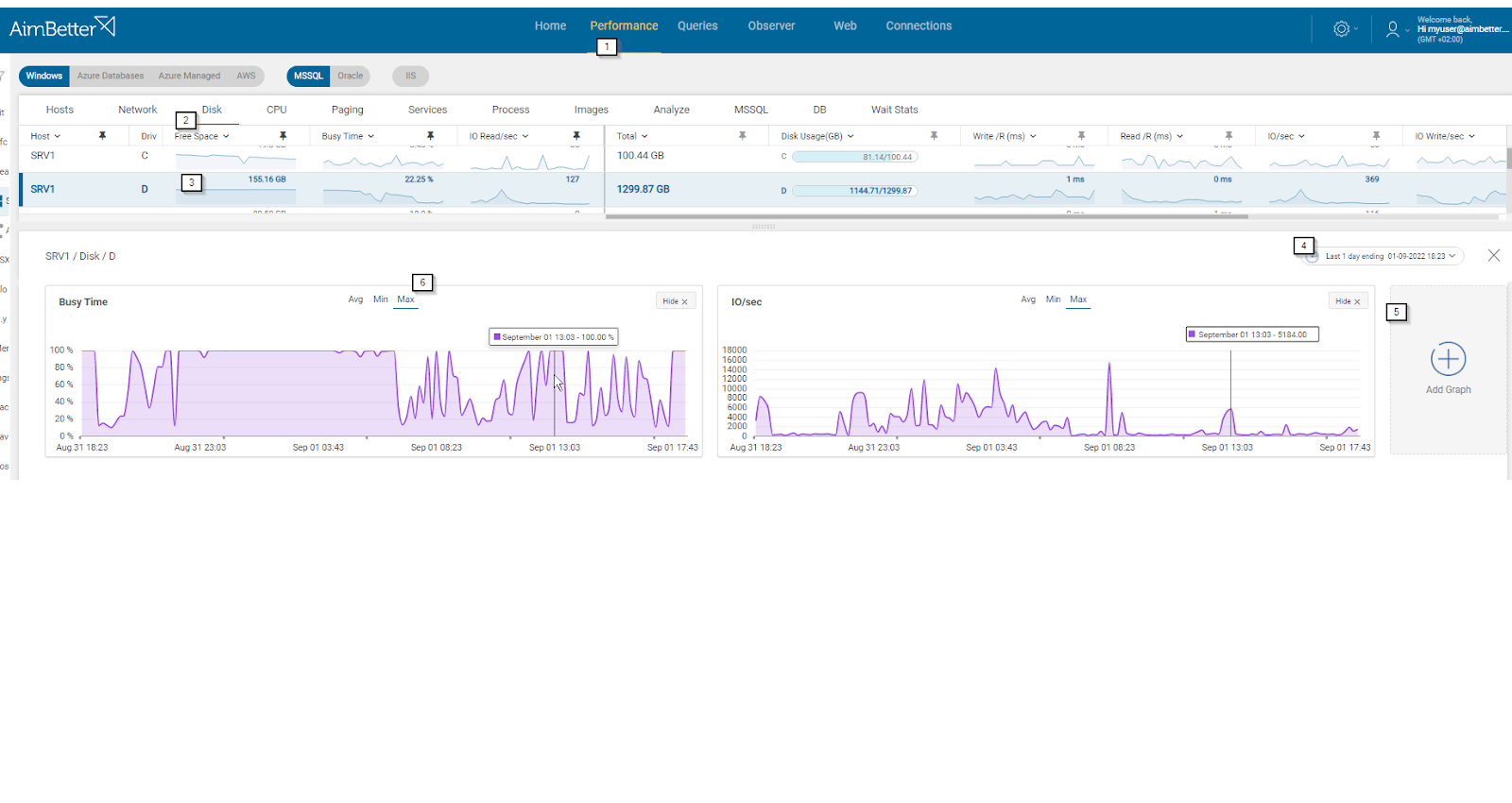
Viewing the current performance of the disk is easy to check with our tool.
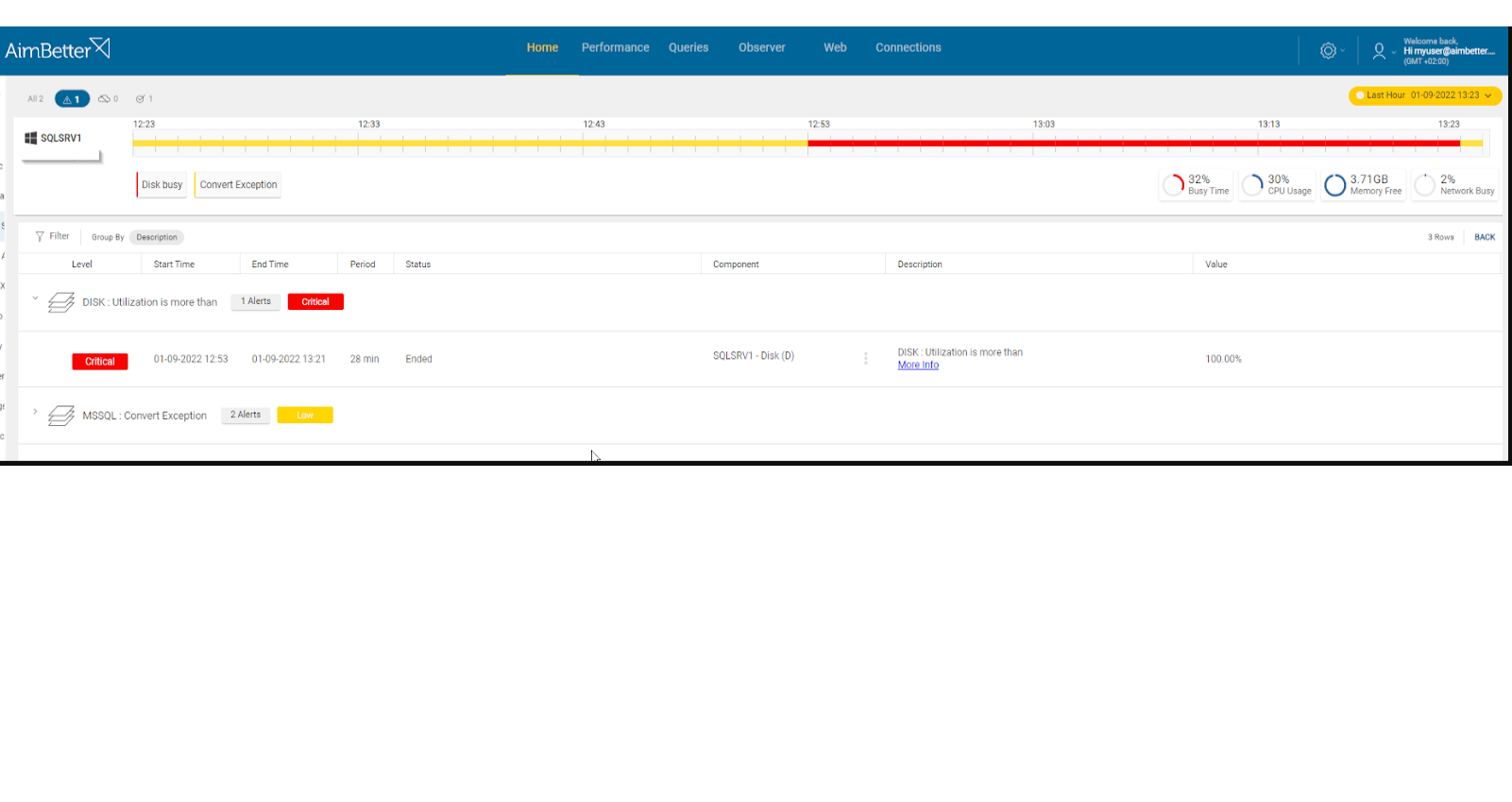
With our system updating logs, tracking tasks that have now and before highly consuming disk I/O is easy.
Our system will notify if files are fragmented when specifically monitoring file connections.
Recommended action:
Avoid running an anti-virus scan during working hours. However, if it’s necessary, exclude database files from the scan. Replace the drive with one that can provide higher performance and I/O utilization. You will probably need downtime for this process.
Improve query performance: redesign the program to maximize the use of indexed data. Redesign table structures to match the requirements of the programs by building indexes. Make use of temporary tables.
Use tools like AimBetter’s Change Tracking to detect unauthorized changes.
Adjust IOPS thresholds based on observed regular activity.
2- Faulty storage hardware Priority: Medium
A storage issue like a bad controller battery or general issue at the Virtual Machine. In addition, possible issues are fragmented files, meaning they are spread out in different parts of the hard drive. Furthermore, disk errors can occur due to the disk’s physical damage. These issues might be related to reading or writing slow responses or a system crash.
Problem identification:
Check the disk I/O performance in order to determine which is the general hardware fault currently.
1. Look for slow write/read speeds. If it occurs, it might cause high disk utilization. This can be tested by running disk benchmarks or monitoring disk activity. However, these checks are not accurate since they relate to the current moment with no history.
2. Look for disk errors. It might be hard to find.
3. Follow up on whether the server or the virtual machine freezes or crashes. If so, then after this event there is a possibility for disk I/O. However, it might be tiring to follow it.
4. Look for connectivity issues with the virtual machine. It might be identified with packet loss. You can read more in this article.
Recommended action :
The faulty hardware component should be replaced immediately.
Consider upgrading infrastructure, like SSDs, for higher IOPS capacity.
Allocate more memory to reduce paging.
3- Running out of disk space Priority: Medium
If the program calls for output to the disk ( I/O ) and the disk is nearly full (generally, the optimal threshold is below 90% of total capacity), the disk will start to slow down as it searches for free space. This will cause the program to wait for progressively longer periods.
Problem identification:
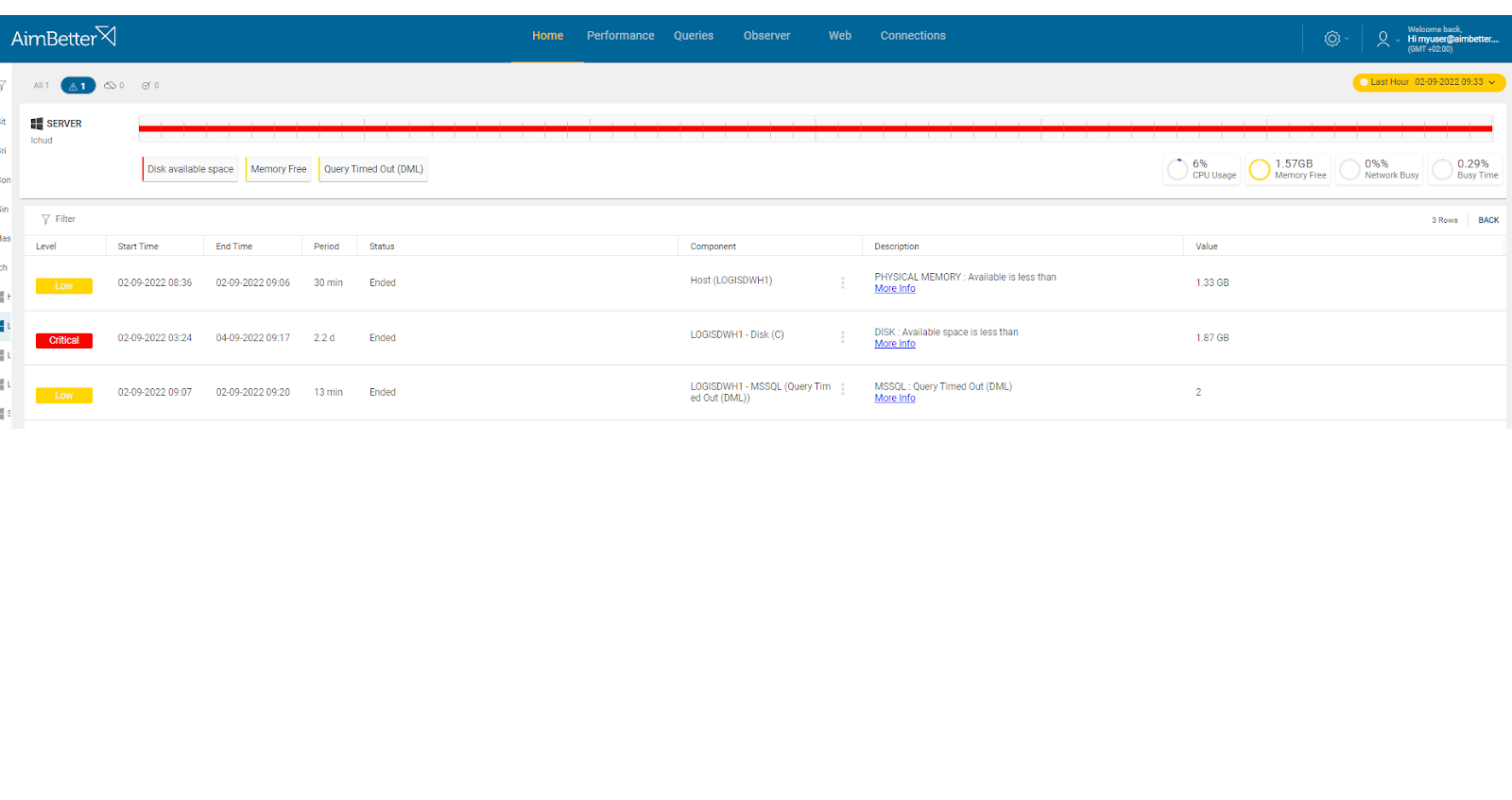
Check if the disk free space is low and run a full scan of the disk’s content in order to locate higher data files.
1. Look for the disk available space using file explorer (for Windows OS). For Linux, you can use the ‘df’ command which displays disk space usage.
2. Run a full scan of the disk’s content to locate its cause.
3. When finding the cause, figure out why this exact file has increased and how to prevent it from happening again. Without proper events history, it might be hard to do.
Recommended action :
Examine the disk free-space reporting. If necessary, working with operating system reports, identify whether there is sufficient space in unnecessary files (for example, old or redundant copies of data), to delete these files and run a disk clean-up. If there is still not enough, further disk capacity must be added.)
4- SQL queries with high disk I/O Priority: Medium
When the program calls for rapid disk reads – typically when searching and analyzing random data, disk utilization will increase rapidly.
Problem identification:
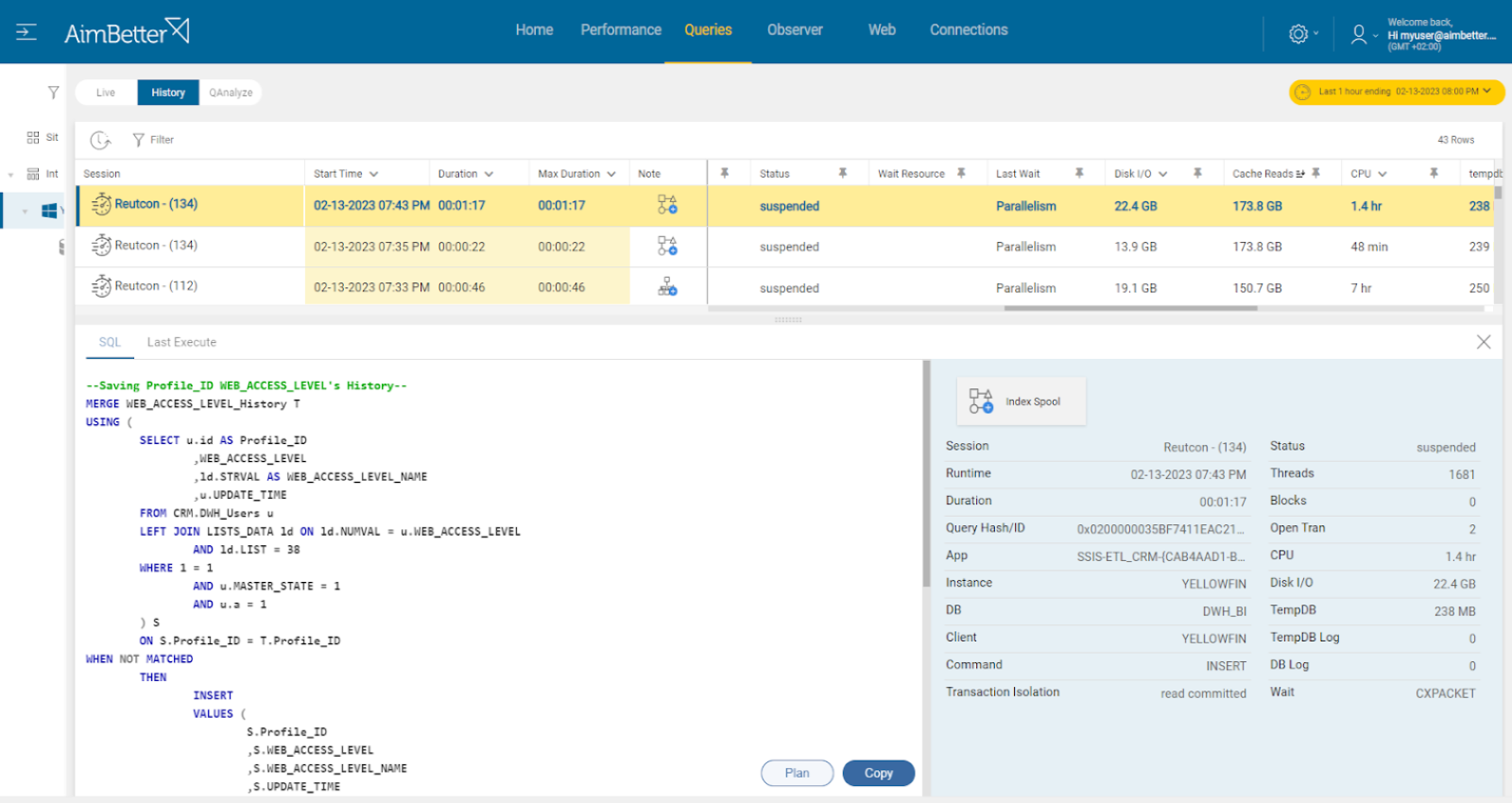
Identify the queries that are highly consuming disk I/O while tracking current disk response times.
1. Identify the highly consuming disk I/O queries by running a performance analysis. You can use SQL Server Profiler for SQL Server or AWS for Oracle. This step is complicated, might take hours (or days) of work, and you can’t guarantee precise results when checking the online status with no historical events.
2. Look for a way to optimize the queries by reducing the amount of I/O utilization they retrieve or by tuning their execution plans. You should consider deleting or adding new indexes. This mission might be complicated, requiring a highly skilled DBA that can view a full SQL query plan that might be long and complicated.
3. While improving the queries, you have to follow up on this issue. If the disk I/O is still high, consider doing a further investigation or looking for other ways to improve the queries.
Recommended action :
Optimize the query performance. This can help reduce the disk I/O consumption of each query. You should consider changing the query’s execution plan or removing and adding indexes.
Redesign program to maximize the use of indexed data. Redesign table structures to match the requirements of the programs by building indexes. Make use of temporary tables.
Tune database settings for optimal performance and limit background jobs during peak hours.
5- Network errors or inefficient network structure Priority: Medium
Faulty or inadequate hardware components, such as routers, controllers, and others with low bandwidth capabilities, can significantly slow down traffic.
Problem identification:
Use a network performance monitoring tool to measure network latency, throughput, and packet loss and check for errors and hardware.
1. Identify where and when the network performance is poor while using a network monitoring tool. In addition, look for times when there’s network packet loss. This task might be hard to follow.
2. Check for errors. This might take time.
3. Analyze network abnormalities, and check for network hardware and settings. Ensure that your network devices are configured for the most optimal performance and function correctly.
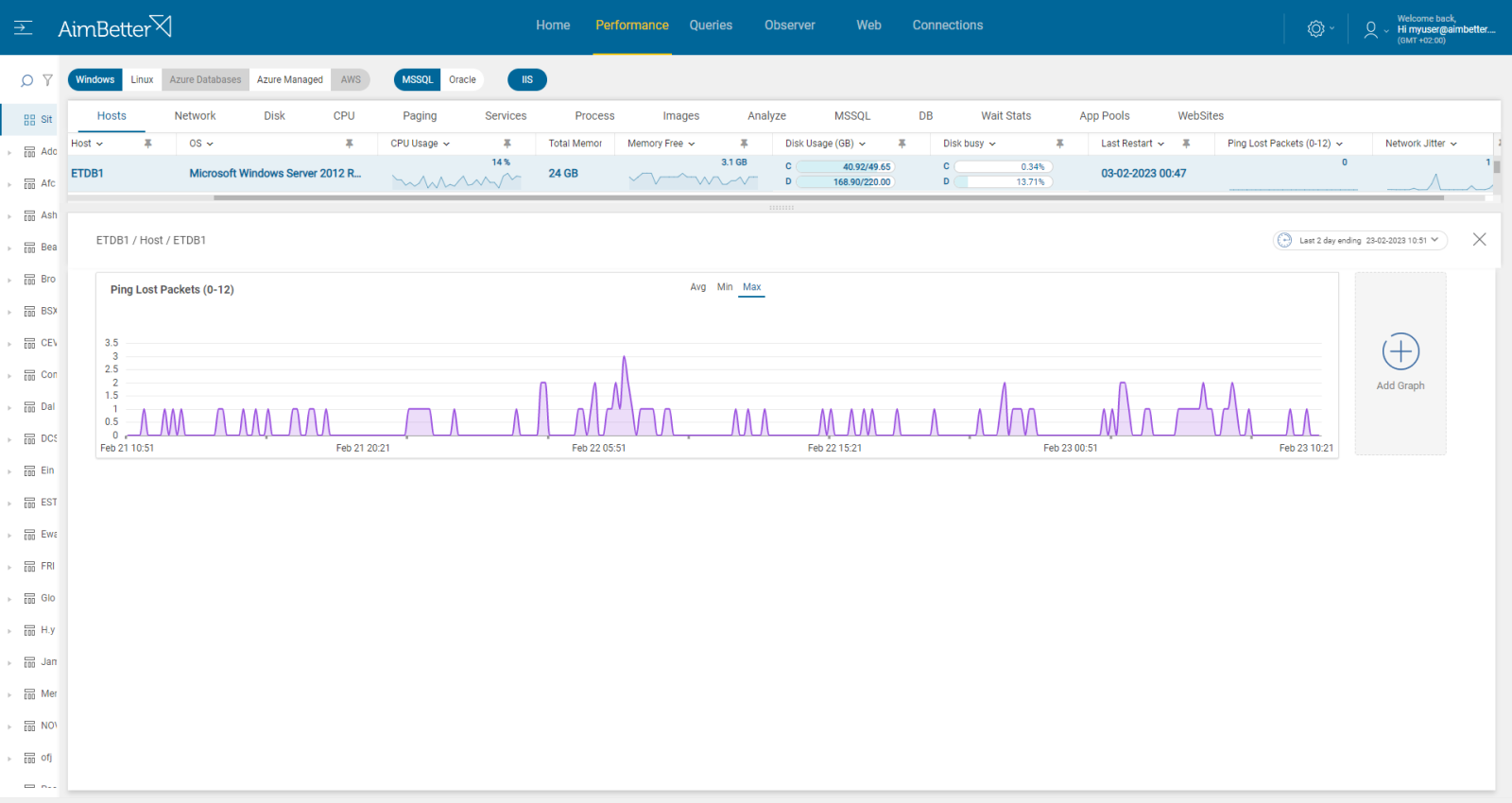
Recommended action:
Investigate all hardware components with your Network Management team. You might change network settings for better performance or improve hardware providing a better bandwidth.
5- Missing indexes or non-optimal query plan Priority: High
Missing indexes will cause extensive data searching from disk, resulting in page swapping. When it happens, SQL Server or Oracle suggests that your query could run faster with a new index.
The same is for non-optimal query plan: a non-optimal query plan increases disk I/O by reading unnecessary data or performing inefficient operations, leading to slower query performance and higher resource usage.
Problem identification:
Identify the missing or corrupt indexes, if they exist, while the disk I/O of the query is high. Investigate queries’ plans that run slowly.
- Identify the missing or corrupt indexes by running a performance analysis. You can use SQL Server Profiler for SQL Server or Oracle Trace for Oracle. This step is complicated and might take hours of work, and you can’t guarantee precise results when checking online status with no historical events.
- Monitor the disk utilization while using performance counters. You lay on current moments. For Linux, use the ‘pidstat’ command, which displays I/O statistics for individual processes.
- Investigate the execution plan of each query that seems to have a high disk I/O. In SQL Server, you can use the “Display Actual Execution Plan” feature. In Oracle, you can use the EXPLAIN PLAN feature. Look for inefficiencies like full table scans, missing indexes, or excessive joins.
- Think about which appropriate indexes would optimize the queries. You can use the Database Engine Tuning Advisor or other tools to help identify the missing indexes. This task requires the expertise of a skilled DBA to review an entire SQL query plan that might be long and complicated.
- Check the existing indexes for corruption. If any index corruption is detected, rebuild or repair the indexes.
- After making changes, if the disk utilization is still high, you may need to investigate the issue further.
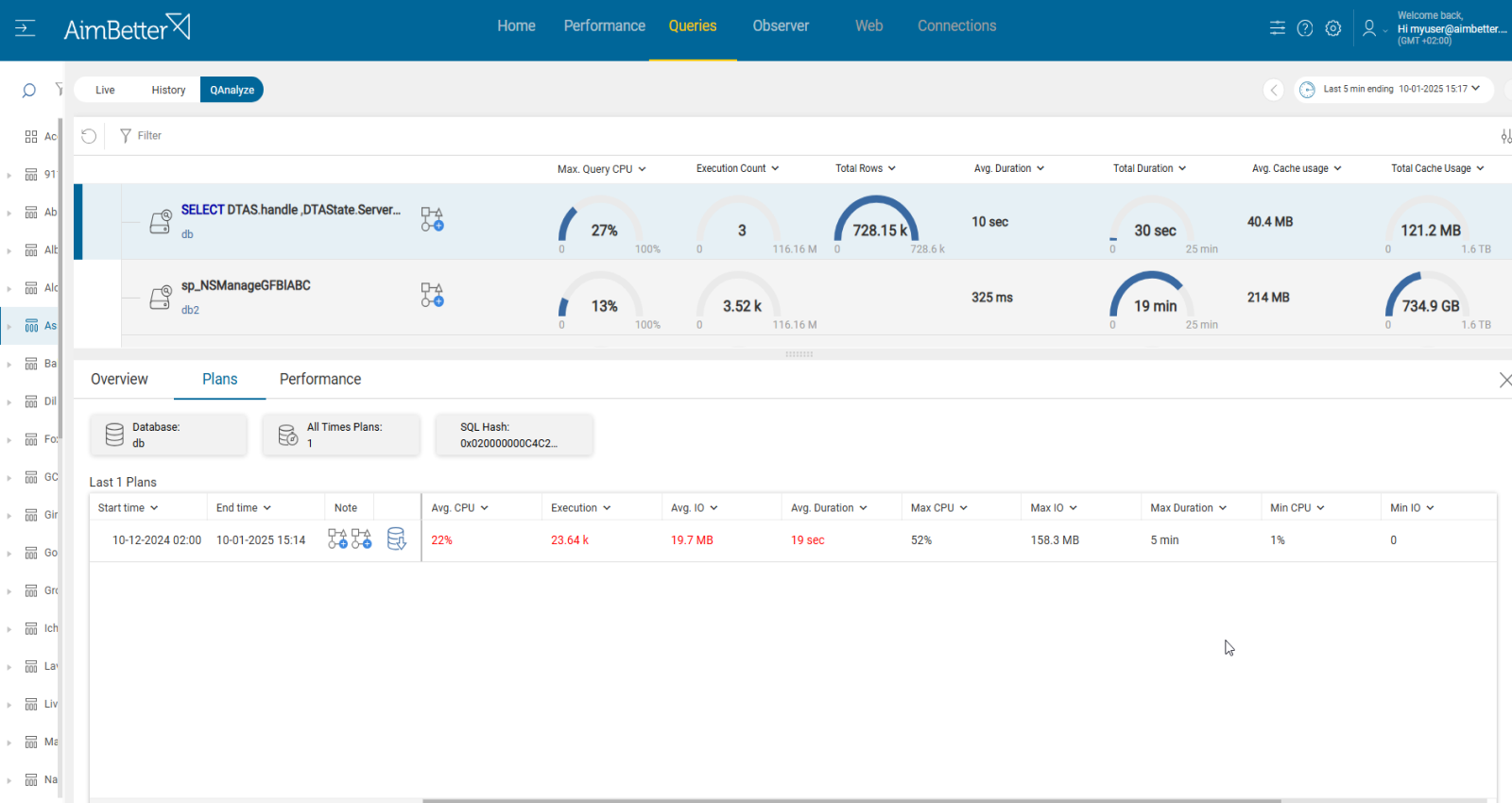
Recommended action:
Identify inefficient queries, implement new indexes, optimize existing ones, and delete corrupted indexes.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}